

NGDC 2021年9月28日
9月28日,中国科学院北京基因组研究所(国家生物信息中心)国家基因组科学数据中心(CNCB-NGDC)组学原始数据归档库(Genome Sequence Archive,简称GSA)的用户汇交数据量突破10 PB(1 PB=1024 TB)。
为存好、管好、用好我国生命组学大数据,解决国内重要数据资源流失和生命组学数据孤岛等问题,提高数据共享率和利用率,北京基因组所于2015年10月建立了国内首个组学原始数据汇交、存储、管理与共享系统GSA,为国家重点研发计划、国家自然科学基金、中科院战略先导专项等国家重大、重点研究计划及任务的科学数据安全管理和归档共享提供了重要支撑。
GSA自上线以来,持续为全球生命科学研究人员提供数据汇交和共享服务,尤其为我国科研人员提供了极大便利。截止2021年9月28日,GSA数据库体系已接收国内外437家研究机构1829名用户的数据递交,支撑科研人员在250种期刊发表研究论文760余篇,为全球110多个国家/地区的用户提供数据服务,平均每天数据下载量达到4 TB。目前 GSA已成为Springer Nature、Elsevier、Wiley、Taylor & Francis及Cell 等国际著名出版集团指定/认可的核酸数据归档库。
随着组学数据的爆炸性增长和数据类型的多样化,面向国家人类遗传资源数据管理的特殊需求,GSA不断丰富完善系统功能,形成了GSA数据库体系,包括GSA,GSA-Human和OMIX。GSA-Human制定人类遗传资源组学数据安全管理机制,实现人类遗传资源数据的分级管理和受控访问,有效保障了国家人类遗传资源数据的安全管理和合理利用,为用户提供人类遗传资源数据受控访问服务;OMIX数据库存储非原始测序数据,如环境组、表型组、代谢组等,它作为上述两种数据资源库的重要补充,有效解决了用户提交除原始测序数据外的其它类型数据的需求。
GSA数据库的建设得到了科技部、中科院以及国家重点研发计划、中科院战略先导专项、信息化专项、国际伙伴计划等项目的大力支持,GSA归档数据使用的大规模计算机硬件设施得到国家财政部改善科研条件专项的长期支持。
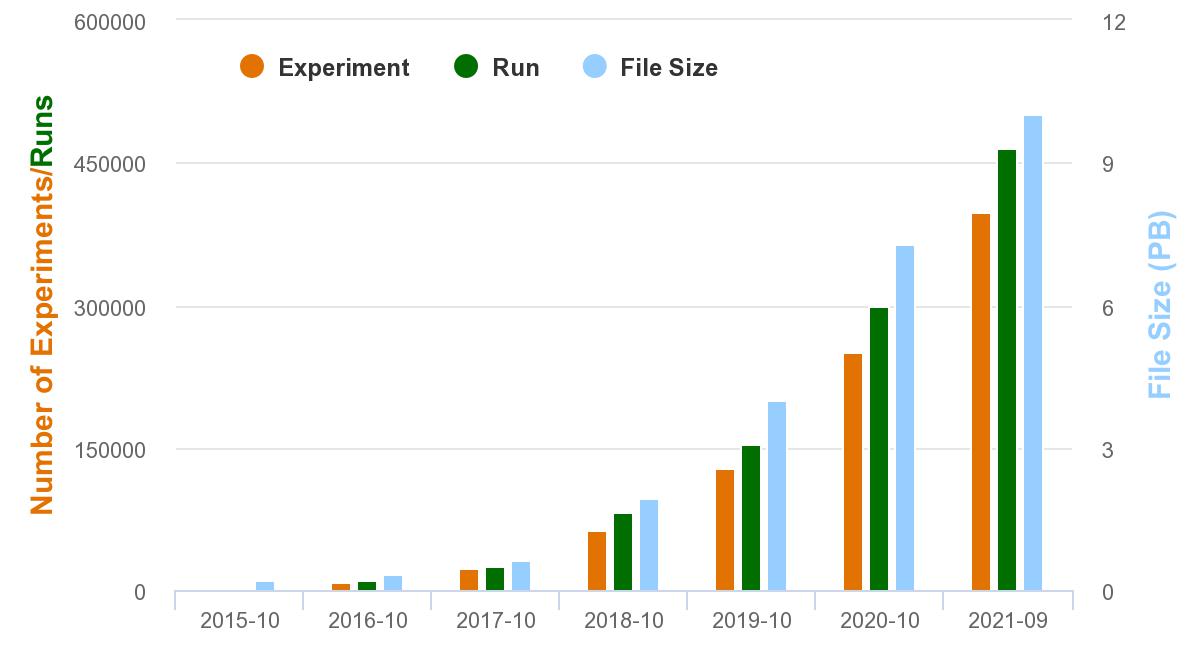
GSA数据量持续增长