

NGDC 2021年9月28日
On September 28, 2021, the raw sequence data archived in the Genome Sequence Archive (GSA) reached 10 PB, a milestone since its inception in October 2015.
GSA is a public archive of raw sequence data in the National Genomics Data Center (NGDC), part of the China National Center for Bioinformation (CNCB), which provides data storage and sharing services for worldwide scientific communities. Importantly, GSA serves as one of the core resources in CNCB-NGDC that has stable state funding in biological data management, thus ensuring long-term persistence and preservation of submitted datasets.
Up to date, GSA has been broadly supported and endorsed by the scientific community, as testified by a total of 398,259 experiments, 465,171 runs, and 10 PB of raw sequence data submitted by 1829 users from 437 institutions. The data have been reported in 760 research articles from 250 scientific journals (as of September 28, 2021). It has been visited by users from over 110 countries/regions, with an average of 4 TB of downloads per day. GSA has been designated as supported data repository by Springer Nature and Elsevier. It is one of the registered repositories in FAIRsharing, and is supported by Wiley and Taylor & Francis.
Considering explosive data growth with diverse data types, the GSA family is expanded into a set of resources for raw data archive with different purposes, namely, GSA, GSA for Human (GSA-Human), and Open Archive for Miscellaneous Data (OMIX). GSA-Human is a data repository specialized in human genetics-related data with controlled access and security. OMIX, as a critical complement to the two resources mentioned above, is an open archive for miscellaneous data. Together, all these resources form a family of resources dedicated to archiving explosive data with diverse types, accepting data submissions from all over the world, and providing free open access to all publicly available data in support of worldwide research activities.
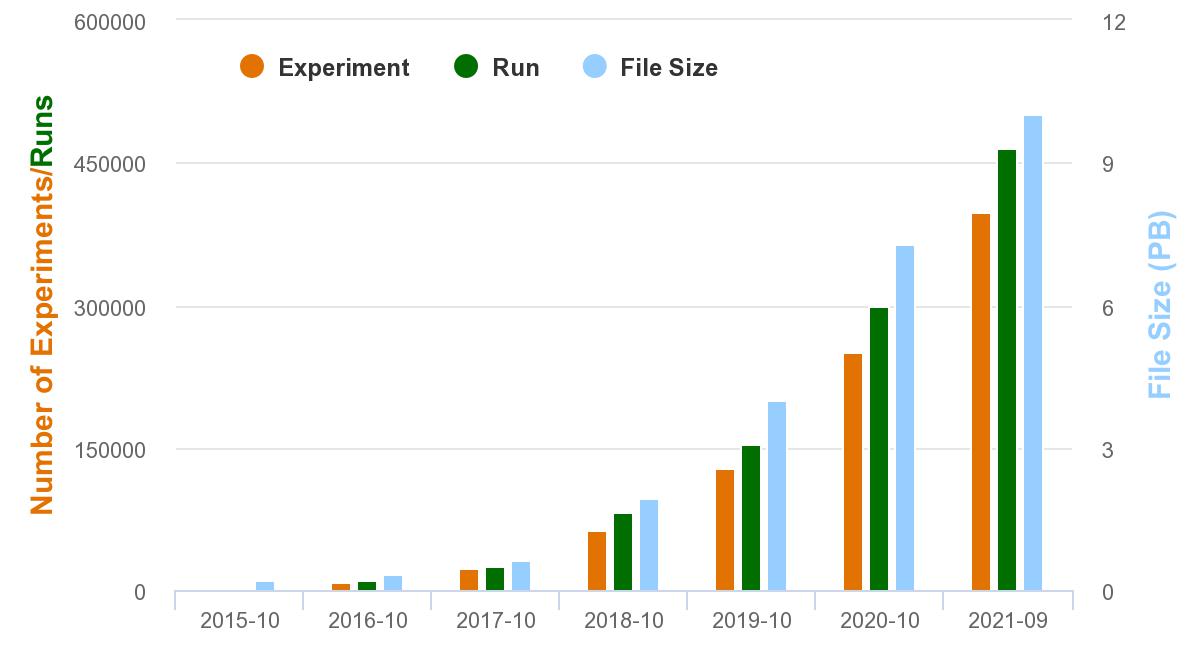
GSA Data Growth