

NGDC Nov 17, 2020
基因组序列变异是基因组DNA上发生的可遗传变异,是物种群体遗传进化、表型差异人类疾病研究、动植物分子育种等最为宝贵的遗传数据资源。近年来,随着测序技术的发展,越来越多物种的基因组被精细解析,来自不同物种不同群体的全基因组序列变异数据呈爆发式增长。
为实现不同生物遗传资源变异组学科学数据的开放共享与安全管理,中国科学院北京基因组研究所(国家生物信息中心)国家基因组科学数据中心开发了国内规模最大的多物种基因组序列变异库GVM(Genome Variation Map),并于2020年9月份完成了数据库2.0版的数据更新与功能升级,研究成果以“Genome Variation Map: a worldwide collection of genome variations across multiple species”为题于11月10日在国际学术期刊《核酸研究》(Nucleic Acids Research)在线发表。
为实现不同生物遗传资源变异组学科学数据的开放共享与安全管理,中国科学院北京基因组研究所(国家生物信息中心)国家基因组科学数据中心开发了国内规模最大的多物种基因组序列变异库GVM(Genome Variation Map),并于2020年9月份完成了数据库2.0版的数据更新与功能升级,研究成果以“Genome Variation Map: a worldwide collection of genome variations across multiple species”为题于11月10日在国际学术期刊《核酸研究》(Nucleic Acids Research)在线发表。
该数据库系统收集了以二代测序和芯片技术为主要检测手段的全基因组序列变异检测的原始数据,通过标准化的变异位点鉴定与注释流程,整合了包括人、畜牧动物、主要农作物和其他资源物种在内的41个物种共计约9.6亿条变异数据信息,64,819个个体的基因型数据,并通过人工审编收录了约26万条高质量的基因型与表型关联知识信息,为深入解析物种遗传变异的功能、研究物种的群体遗传多样性、解读表型/性状的遗传机制等提供了重要数据资源。
GVM数据库通过对变异相关的原数据、变异信息与知识数据分别进行结构化整理,开发了界面友好的数据检索、浏览、汇交、下载、统计等模块,用户可以方便、快捷地浏览入库物种、项目、样本、变异、关联知识和用户递交数据的详细信息。通过页面检索,还可便捷的获取一个物种群体内的所有变异数据及功能知识信息、变异注释基因及功能、群体频率等信息,并可通过ftp服务下载VCF和FASTA格式的全基因组序列变异数据。
GVM数据库积极响应基因组科学数据管理与共享工作要求,建立了基因组序列变异数据的在线汇交模块,提供在线批量数据递交服务,为数据递交者提供账号管理,并为每一个递交数据分配唯一可识别的标识符,根据递交用户设定的数据公开时间进行可控管理。依托中心高性能存储和异地容灾的备份机制,定期进行数据更新与异地备份,以全面保证数据的完整性与安全性。
北京基因组所(国家生物信息中心)章张研究员和宋述慧副研究员为本文共同通讯作者,李翠萍、田东梅、唐碧霞、刘晓楠、滕徐菲为共同第一作者。该研究得到了中科院战略性先导科技专项、中科院国际大科学计划、国家科技攻关计划、中科院青年创新促进会等的资助。
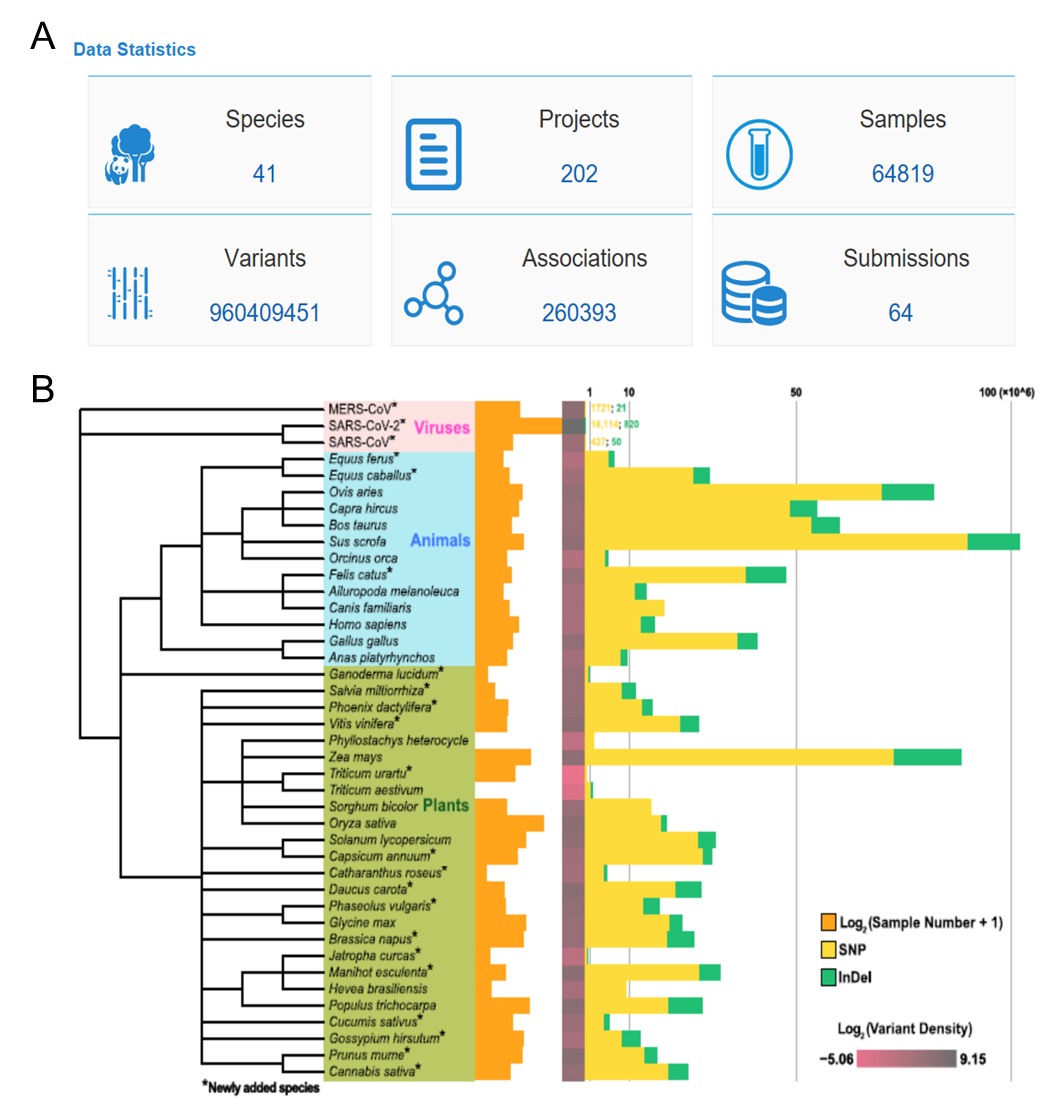
GVM数据库(A)六大数据模块及数据量(B)各物种变异数据量及密度统计图
基因组序列变异是基因组DNA上发生的可遗传变异,是物种群体遗传进化、表型差异人类疾病研究、动植物分子育种等最为宝贵的遗传数据资源。近年来,随着测序技术的发展,越来越多物种的基因组被精细解析,来自不同物种不同群体的全基因组序列变异数据呈爆发式增长
d是基因组DNA上发生的可遗传变异,是物种群体遗传进化、表型差异人类疾病研究、动植物分子育种等最为宝贵的遗传数据资源。近年来,随着测序技术的发展,越来越多物种的基因组被精细解析,来自不同物种不同群体的全基因组序列变异数据呈爆发式增