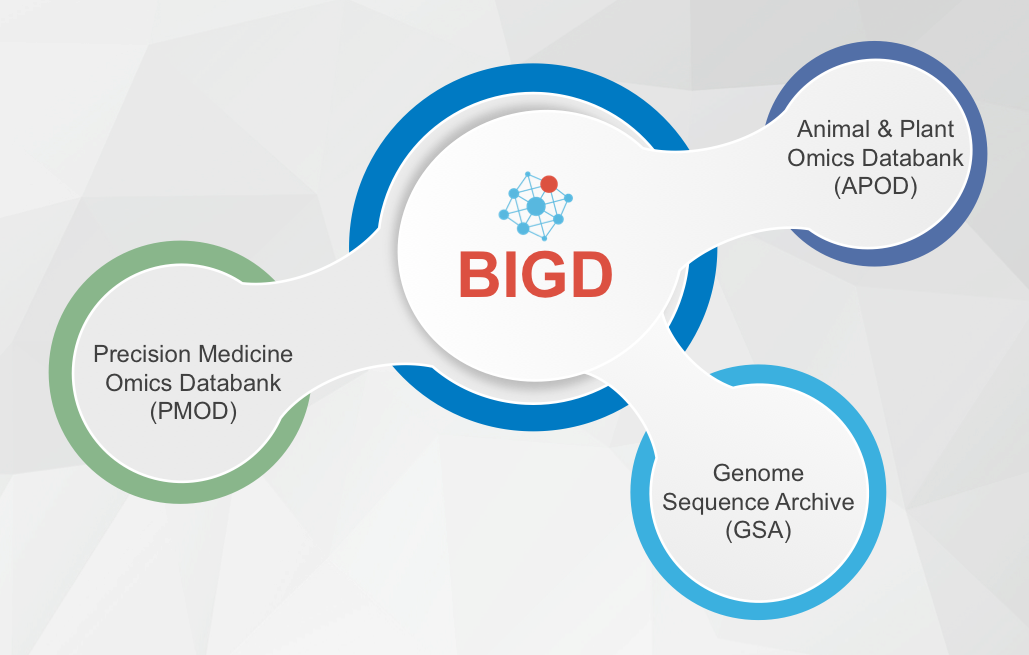
国家基因组科学数据中心的定位与目标是,面向我国人口健康和社会可持续发展的重大战略需求,围绕国家精准医学和重要战略生物资源的组学数据,建立海量生物组学大数据储存、整合与挖掘分析研究体系,发展组学大数据系统构建、挖掘与分析的新技术、新方法,建设组学大数据汇交、应用与共享平台。中心主要涵盖以下三个部门:
原始组学数据部门 Branch of Genome Sequence Archive (GSA)
-
存储多种高通量测序的海量原始组学数据资源
-
建立符合国际标准的原始组学数据归档库
-
形成中国原始组学数据的共享平台
精准医学组学数据部门 Branch of Precision Medicine Omics Databank (PMOD)
-
整合公共个人组学数据,建立不同人群的基因组参考序列
-
完善建立中国人群基因组遗传变异图谱
-
形成中国人群精准医学信息库,为疾病的诊疗提供更为有效的方法
重要动植物组学数据部门 Branch of Animal & Plant Omics Databank (APOD)
-
围绕国家重要战略生物资源
-
建立海量组学数据的整合、挖掘与应用体系
-
形成综合性的多组学数据库系统
此外,还有专门的信息系统管理部门给予技术和服务支持
信息系统管理部门 Branch of Information & System Management (ISM)
-
负责网络以及系统基础设施的管理
-
管理和维护机房服务器,提供安全可靠的Web系统。
-
与其他部门协调,确保BIGD所有资源都始终安全可靠。